Algorithm
本周完成的算法题: Permutations
题目要求:
1
| |
本题可以通过回溯法来解决,需要注意排除重复添加元素的情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
Review
本周Review Introduction to Java 8 Parallel Stream
本文主要讲述了什么时候应该使用Parallel Stream。文中提到Parallel Stream要比Sequential Stream 花费更多的时间在线程协调上,所以在使用Parallel Stream 之前你需要考虑一下的几个因素:
- 要处理的数据集要大
- Java使用
ForkJoinPool来达到并行的目的。所以源头的集合要可切分(Splitable),ArrayList 要比 LinkedList 要好 - 现在确实有性能上的问题
- 要处理好数据共享的问题
通过NQ模型(来自 Brian Goetz)可以衡量是否要做并行化:
1
| |
其中:
N = 数据集中的条目数量(number of items in the dataset) Q = 每个条目需要的工作(amount of work per item)
解释起来就是:如果数据集多但是每个条目需要工作少,或者数据集不多但是每个条目需要的工作多,你就可以通过并行化来获的性能上的优化。
Tip
上面Review提到Parallel Stream使用到了ForkJoinPool,这中间一个小细节需要注意:
默认情况下所有的Parallel Stream都是共用ForkJoinPool.common这个池子,所以如果Stream后的任务比较耗时(比如有网络请求等),会堵塞住整个池子,导致其他的Stream也会被影响到。
如果不想被其他的影响也不想影响其他,可以通过自定有的池子来执行。以下是一个示例:
1 2 3 4 5 6 7 8 9 | |
参考:
Think Twice Before Using Java 8 Parallel Streams
Custom thread pool in Java 8 parallel stream
Share
在项目中碰到了一个因为超大规模的数据(30亿)导致原本执行挺快的模块连续执行超过1天也没有执行完,而且也看不到执行完的希望。于是开始排查是哪里出现了问题。
背景描述
业务方基于业务需要配置了约11000条规则,每个规则都是对某个实体的属性判断,最终保存到系统是类似如下的表达式:
1
| |
我们需要给出每个规则会命中哪些数据,或者说每条数据会命中哪些规则。
原始方案
在最开始的实现中,我们是把规则当做一个求值表达式,通过内部的一个DSL引擎对每个规则来做判断,如果返回true就说明命中规则,如果是false说明没有命中规则。
单条规则每次求值时间在0.04ms,11000条规则每次执行需要44ms左右,在个人机器上测试10w条数据需要大概4000s,这个时间完全不可接受的。
分析问题
经过数据分析发现就是无效的规则执行太多了,在数据确定的情况下,很多规则是肯定不会命中的。比如有一条数据是这样的:
1 2 3 | |
那它实际需要执行的规则是那些规则条件中包含了 育儿书、中信出版社、小蘑菇的规则,至于其他不包含这些的规则肯定是不会命中的,也就无需执行了。
所以解决方案是:预先为属性、属性值、规则之间建立类似倒排索引的结构,通过属性值来查找可能要执行的规则,然后再执行。
解决方案
在解决方案细节中我们需要额外考虑的一点是操作符的问题。对于不同的操作符需要做不同的设计:
- 对于 Equal(=) 是可以直接通过值来获取到所有有关系的规则。
>>=<<=innot in等操作符需要做进步一求值才行,但是考虑这些操作符总体使用数量很少,那就直接把这些规则都加到候选规则集中,由求值引擎统一执行即可。
假设我们现在有三个属性 product_word,press,author 以及两个操作符 = in,那么最终构成的索引结构如下图:
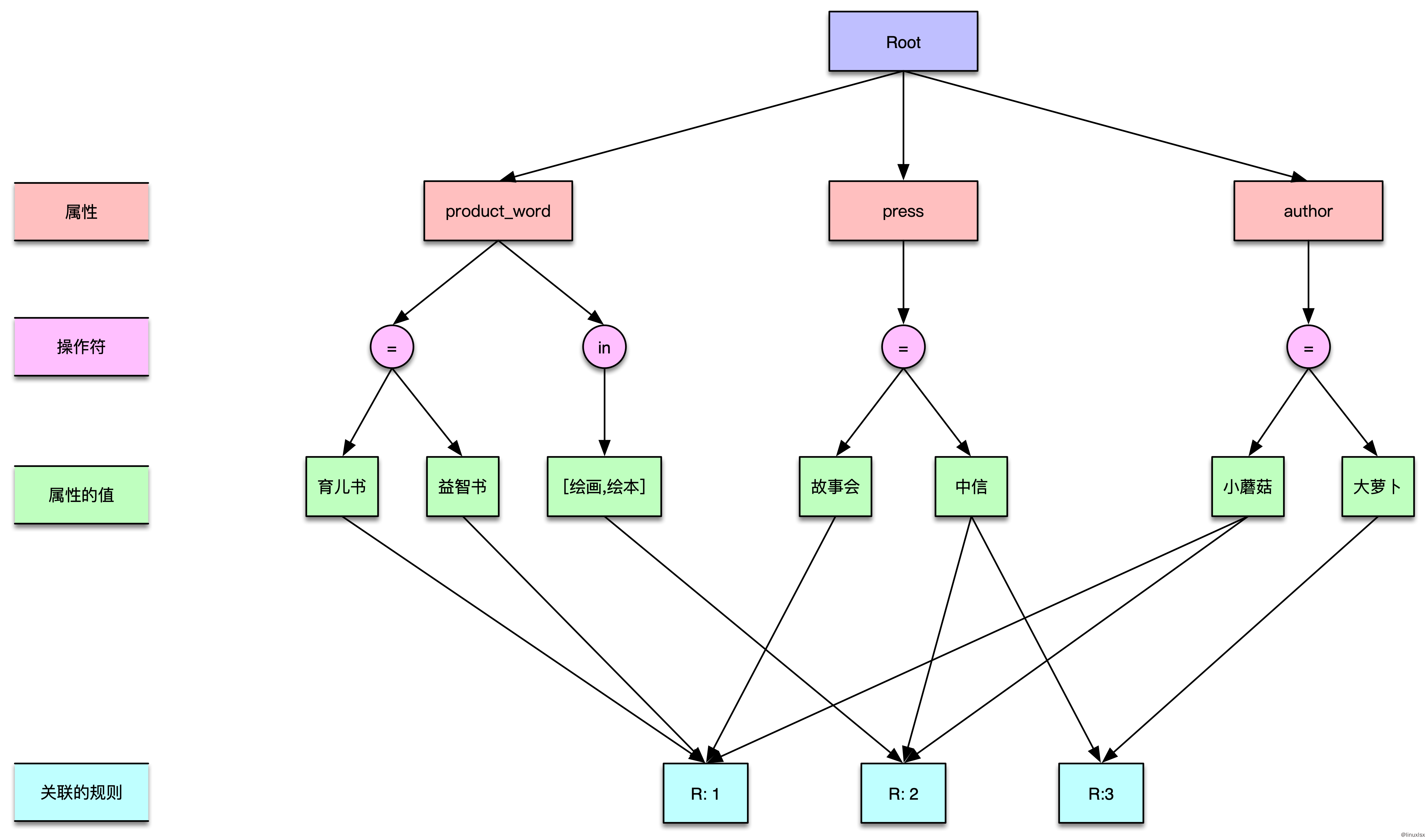
上下层级之间实现都是一个HashMap结构,可以快速的定位到目标数据。有了这个结构后再来看看当输入以下这条数据的时候,需要执行哪些规则:
1 2 3 | |
- 通过
product_word = 育儿书可以找到规则R:1 product_word还有一个in操作符,根据前面提到的原则把这个操作符关联的规则全部加入候选集。现在的规则包含R:1R:2- 通过
press = 中信出版社可以找到规则R:1 - 通过
author = 小蘑菇可以找到规则R:1
最后要执行的规则集为 [R:1, R:2],比原来的方案要少执行了规则R:3。
使用这个方案后实际上一条数据最多可能需要执行的规则为100条,更多的少于10条。在本地测试同样执行10w条数据,只需要27s,性能提升将近150倍。
总结
在大规模数据处理中,尽可能的减少输入数据量,减少关键步骤执行次数和时间是优化性能的两大利器。